
LambdaでKinesis Video Streamsの音声ストリームをパースしてステレオ音声化する

📅 2020-05-21
Amazon Connectでライブメディアストリーミングを有効にし、問い合わせフロー内で有効にした場合Kinesis Video Streams(以下KVS)上に音声ストリームが保存されますが、そのデータは純粋な音声データではなくMatroskaというコンテナフォーマットで保存されます。
AWS公式でもストリームパーサーライブラリというものがありますが、こちらは言語的にはJavaのみが公開されています。
私はJavaが苦手だというのと、Lambdaで簡単に実装できるNode.jsでストリームをパースしてFFmpegでステレオ音声化するものを作ってみました。
※今回のソースはリアルタイムに処理をするものではなく、通話終了後のストリームを処理するものになります。
【補足】ライブメディアストリーミングの用途
ライブメディアストリーミンを有効にすることでやり取りの中でリアルタイムに音声をキャプチャすることができます。これによりなにができるかというと、
- リアルタイム音声認識
- チャットボットとの連携
- 音声入力IVR
- 留守番電話録音機能
などです。
Amazon Connect標準の通話録音機能は、通話終了後に一定時間経たないとS3上でアクセスできないため、よりリアルタイムに音声データを扱いたい場合にはKinesis Video Streamsを利用する必要があります。
また、Amazon Connectの標準の通話録音はエージェントに接続されないと保存されないという仕様になっているため、IVRのみで完結する場合やV字発信などの仕組みの場合にはKVS経由で録音を行う必要があります。
Lambdaの設定
FFmpegを使用するために
FFmpegをLambdaで実行するにあたり、以下のリンクよりLinux上で動作するビルド済みのFFmpegをダウンロードしましょう。ffmpeg-4.0.3-64bit-static.tar.xzが安定して動くかと思います。
ダウンロードしたファイルを解凍し、Lambdaレイヤーもしくはソースパッケージの中に含みます。今回はLambdaレイヤーを利用しました。
LambdaのIAMロール
必要な権限は
- AWSLambdaBasicExecutionRole
- AmazonKinesisVideoStreamsReadOnlyAccess
- 保存先S3への書き込み権限
になります。
メモリとタイムアウト設定
タイムアウトは最大値の15分に、メモリの目安は以下です。
| 通話時間 | 実行時メモリ |
|---|---|
| 10分 | 350MB |
| 30分 | 660MB |
詳細は後述しますが、一番時間がかかる処理がKVSのgetMediaでストリームを取得する部分で、15分内で処理可能な最大通話時間が約2時間くらいになります。
ですので、メモリは余裕をもって2048MBに設定しました。
必要なパラメーター
- ストリーム名
- startFragmentNumber
の2点があればOKです。その他付加情報をつけたい場合にはCTRから情報を紐付けると良いでしょう。
ソースコード
const AWS = require('aws-sdk');
const ebml = require('ebml');
const fs = require('fs');
const { execSync } = require('child_process');
const region = 'ap-northeast-1';
const bucketName = 'ステレオ音声の保存先を指定';
var start = new Date();
exports.handler = async (event) => {
const streamName = "ストリーム名を指定";
const fragmentNumber = "StartFragmentNumberを指定";
const s3 = new S3(AWS, region);
const raws = await getMedia(streamName, fragmentNumber);
fs.writeFileSync("/tmp/from.wav", Converter.createWav(raws.from, 8000));
fs.writeFileSync("/tmp/to.wav", Converter.createWav(raws.to, 8000));
execSync('/opt/bin/ffmpeg -i /tmp/from.wav -i /tmp/to.wav -filter_complex "[0:a][1:a]join=inputs=2:channel_layout=stereo[a]" -map "[a]" /tmp/mixed.wav');
await s3.put(bucketName, "mixed.wav", fs.readFileSync("/tmp/mixed.wav"));
const response = {
statusCode: 200,
body: JSON.stringify('End Stream Parse!'),
};
return response;
};
class S3 {
constructor(AWS, region){
this._s3 = new AWS.S3({region:region});
}
async get(bucketName, key){
const params = {
Bucket: bucketName,
Key: key
};
return await this._s3.getObject(params).promise();
}
async put(bucketName, key, body,) {
const params = {
Bucket: bucketName,
Key: key,
Body: body
};
return await this._s3.putObject(params).promise();
}
}
async function getMedia(streamName, fragmentNumber) {
// Endpointの取得
const kinesisvideo = new AWS.KinesisVideo({region: region});
var params = {
APIName: "GET_MEDIA",
StreamName: streamName
};
const end = await kinesisvideo.getDataEndpoint(params).promise();
// RAWデータの取得
const kinesisvideomedia = new AWS.KinesisVideoMedia({endpoint: end.DataEndpoint, region:region});
params = {
StartSelector: {
StartSelectorType: "FRAGMENT_NUMBER",
AfterFragmentNumber:fragmentNumber,
},
StreamName: streamName
};
const data = await kinesisvideomedia.getMedia(params).promise();
const decoder = new ebml.Decoder();
const arraySize = 8 * 1024 * 1024;
let audioFromCustomer = new Uint8Array(0);
let audioToCustomer = new Uint8Array(0);
let fromLength = 0;
let toLength = 0;
let fromCurrentLength = 0;
let toCurrentLength = 0;
decoder.on('data', chunk => {
const name = chunk[1].name;
const payload = chunk[1].payload;
if (name == "SimpleBlock") {
const track = chunk[1].track;
if (track == 1 ) {
let nextLength = toCurrentLength + payload.length;
if (nextLength > toLength) {
toLength += arraySize;
let tmpAry = audioToCustomer;
audioToCustomer = new (tmpAry.constructor)(toLength);
audioToCustomer.set(tmpAry, 0);
}
audioToCustomer.set(payload, toCurrentLength);
toCurrentLength += payload.length;
} else if (track == 2) {
let nextLength = fromCurrentLength + payload.length;
if (nextLength > fromLength) {
fromLength += arraySize;
let tmpAry = audioFromCustomer;
audioFromCustomer = new (tmpAry.constructor)(fromLength);
audioFromCustomer.set(tmpAry, 0);
}
audioFromCustomer.set(payload, fromCurrentLength);
fromCurrentLength += payload.length;
}
}
});
decoder.write(data["Payload"]);
return {
from: audioFromCustomer.slice(0, fromCurrentLength).buffer,
to: audioToCustomer.slice(0, toCurrentLength).buffer
};
}
class Converter {
// WAVファイルの生成
static createWav(samples, sampleRate) {
const len = samples.byteLength;
const view = new DataView(new ArrayBuffer(44 + len));
this._writeString(view, 0, 'RIFF');
view.setUint32(4, 32 + len, true);
this._writeString(view, 8, 'WAVE');
this._writeString(view, 12, 'fmt ');
view.setUint32(16, 16, true);
view.setUint16(20, 1, true); // リニアPCM
view.setUint16(22, 1, true); // モノラル
view.setUint32(24, sampleRate, true);
view.setUint32(28, sampleRate * 2, true);
view.setUint16(32, 2, true);
view.setUint16(34, 16, true);
this._writeString(view, 36, 'data');
view.setUint32(40, len, true);
let offset = 44;
const srcView = new DataView(samples);
for (var i = 0; i < len; i+=4, offset+=4) {
view.setInt32(offset, srcView.getUint32(i));
}
return view;
}
static _writeString(view, offset, string) {
for (var i = 0; i < string.length; i++) {
view.setUint8(offset + i, string.charCodeAt(i));
}
}
}ストリームのパース
Matroskaのデータ構造はEBMLパーサーで解析可能です。解析した中身の詳細は割愛しますが、
- AUDIO_FROM_CUSTOMER
- AUDIO_TO_CUSTOMER
という2つのストリームに分かれているため、それらのpayloadを取得してBufferに蓄積していきます。
Bufferは更新する度にインスタンスを作成すると非常に動作が重くなるので、上記スクリプトでは8MB単位で作成し足りなくなったら都度8MB拡張して再作成をしています。
ffmpegで2つのモノラル音声を結合してステレオ化
ストリームをパースするとL/Rのrawデータをすることができるので、それぞれwavヘッダーをつけた後に結合します。
ffmpeg -i left.mp3 -i right.mp3 -filter_complex "[0:a][1:a]join=inputs=2:channel_layout=stereo[a]" -map "[a]" output.mp3実行時間と消費メモリ
前述しましたが、このソースで処理可能な最大通話時間は約2時間です。どこがボトルネックかと言うとgetMediaAPIのストリーム取得速度です。
以下の画像は30分の通話を1024MBのメモリ設定で実行した際の時間記録のログになりますが、実行時間188秒のうち、getMediaAPIでストリームを取得するのに180秒近くかかっています。
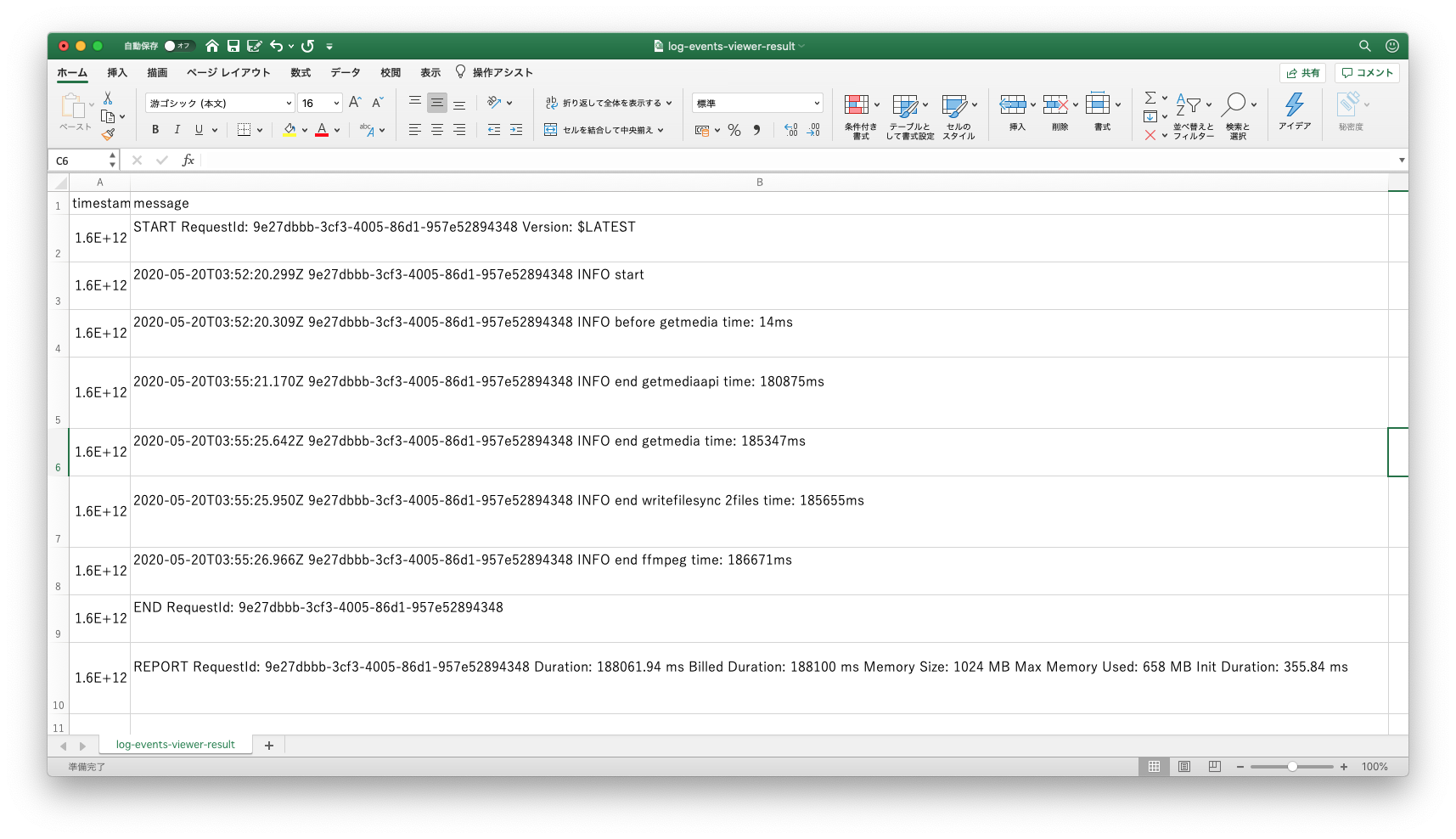
取得したストリームのパース、wav変換、/tmp以下への書き出し、ffmpegでのステレオ化にはほとんど時間がかかりません。
実行メモリはやはり取得したストリームデータをメモリ上に保持するということと、パースの際に一時的に複数のバッファを作成することから多く消費します。
以上から、超長時間の通話をリソース効率よく処理するにはgetMediaAPIは向いていないということがわかります。
まとめ
KVS上の双方向通話ストリームデータをパースし、ステレオ化する方法の紹介でした。話題のリアルタイム音声認識やチャットボット連携に上記のソースでは対応できませんが、Matroskaコンテナのパース部分は活用できると思います。
EBMLのパーサーライブラリ自体は様々な言語であると思うので、別の言語での実装も比較的簡単にできると思います。
Amazon Connectのライブメディアストリーミング処理の参考になれば幸いです。